
外部ライブラリ「Pandas」を使って、CSVファイルを読み込みます。
読み込むCSVは、オープンデータにしました。[br num=”1″]気象庁の過去の気象データです。
出典:気象庁|「最新の気象データ」CSVダウンロード データ部掲載内容(1、3、6、12、24、48、72時間降水量)[br num=”1″] 最新のCSVファイル
ローカルのDドライブなどにダウンロードして読み込む方法や、URLを指定して直接読み込む方法を紹介します。
Pandasのインストール
表データを扱う外部ライブラリ「Pandas」。[br num=”1″]インストールがまだの場合は、ここで入れておきましょう。
Windowsの場合、次のコマンドで行います。
pip install pandas
Macの場合は、pipの部分がpip3になります。
初めてライブラリをインストールするという方は、もしかするとエラーに悩まされるかもしれません。[br num=”1″]こちらの記事で解決方法を解説していますので、参考にしてみてください。
ローカル環境のCSVファイルを読み込む
まずはローカル環境のCSVファイルを読み込みます。[br num=”1″]ここでは、Pythonのソースファイルと同じ階層に「data」フォルダを作成し、その中に格納したCSVファイルを読み込んでいます。
文字コードがUTF-8の場合、そのまま読み込める
冒頭で書いた気象庁の気象データのCSVファイルです。[br num=”1″]UTF-8で保存しました。
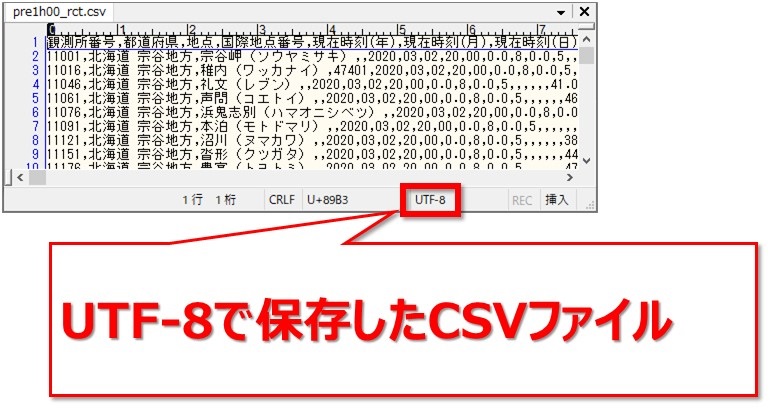
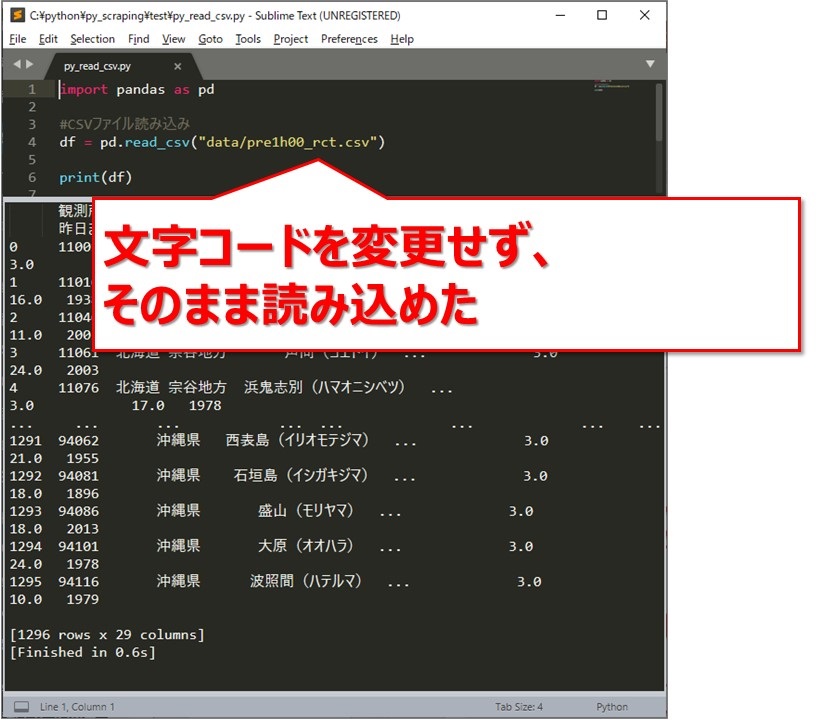
次のソースコードで実行してみます。[br num=”1″]解説は後述します。
import pandas as pd
#CSVファイル読み込み
df = pd.read_csv("data/pre1h00_rct.csv")
print(df)
文字コードを指定しなくても、そのまま読み込めました。
使用するライブラリを、最初にインポートします。
import pandas as pd
as pd のように書けば、ライブラリを使うときpdと短く表記できます。[br num=”1″]as pd を書かない場合、読み込むところはこんな感じ。
df = pandas.read_csv("data/pre1h00_rct.csv")
ちょっと長くなりますね。
ライブラリのread_csvを使って、dataフォルダ内のCSVファイルを読み込んでいます。[br num=”1″]そして、読み込んだデータを、データフレームのdfに格納しています。
最後に、
print(df)
でdfを表示させます。
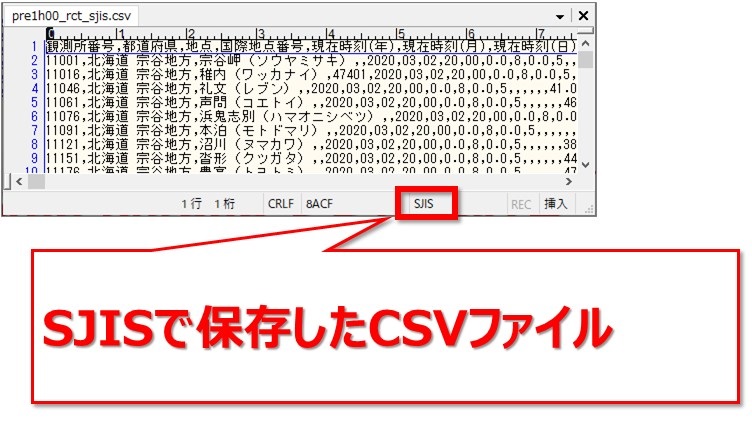
SJISなどの場合、SHIFT-JISを指定して読み込む
UTF-8で保存していたCSVファイルをコピペして、SJISで保存しなおしました。
UTF-8のときと同じように読み込もうとすると、次のようにエラーが表示されてしまいます。

どうやらSHIFT-JISを指定しないといけないようです。[br num=”1″]「えっ、SJISで保存したんじゃないの?」と思われるかもしれません。
そうなんです。[br num=”1″]SJISとSHIFT-JISが同じものだと思っていた頃が私にもありました・・・。[br num=”1″]同じならエラーにならないんですけんどね。
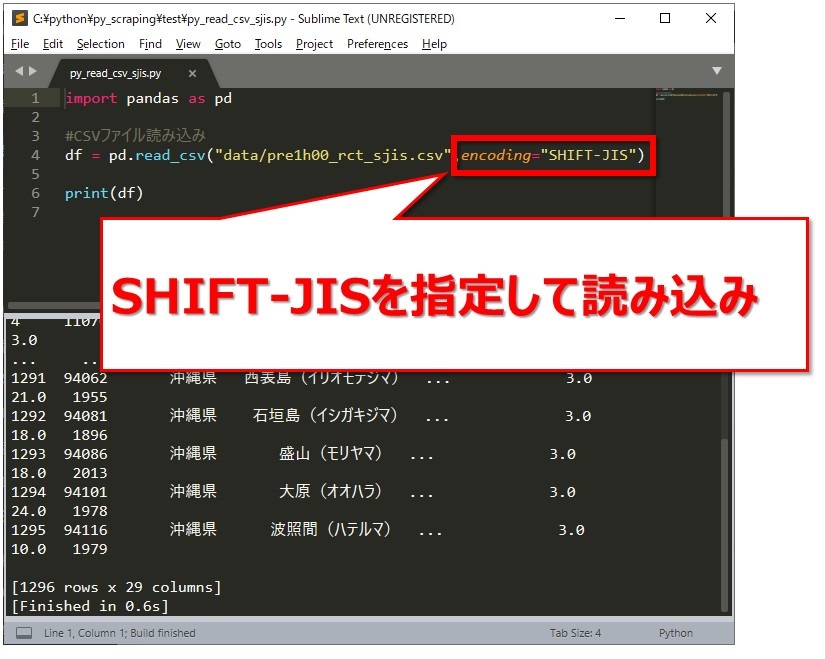
というわけで、SHIFT-JISを指定した場合のソースがこちら。
import pandas as pd
#CSVファイル読み込み
df = pd.read_csv("data/pre1h00_rct_sjis.csv",encoding="SHIFT-JIS")
print(df)
保存して実行してみます。[br num=”1″]ちゃんと読み込めました。
一部の行を指定して読み込む
こんどはスクレイピングしていきます。
行指定の例です。[br num=”1″]1つずつ解説していきますね。
import pandas as pd
#CSVファイル読み込み
df = pd.read_csv("data/pre1h00_rct.csv")
#3,4,5行目を表示
print(df.loc[[3,4,5]])
#都道府県の列が東京都の行を表示
data_tokyo = df[df["都道府県"]=="東京都"]
print("東京都です\n", data_tokyo)
#都道府県の列に北海道を含む行を表示
data_hokkaido = df[df["都道府県"].str.contains("北海道")]
print("北海道です\n", data_hokkaido)
行数を指定する
まずは行数を指定する場合
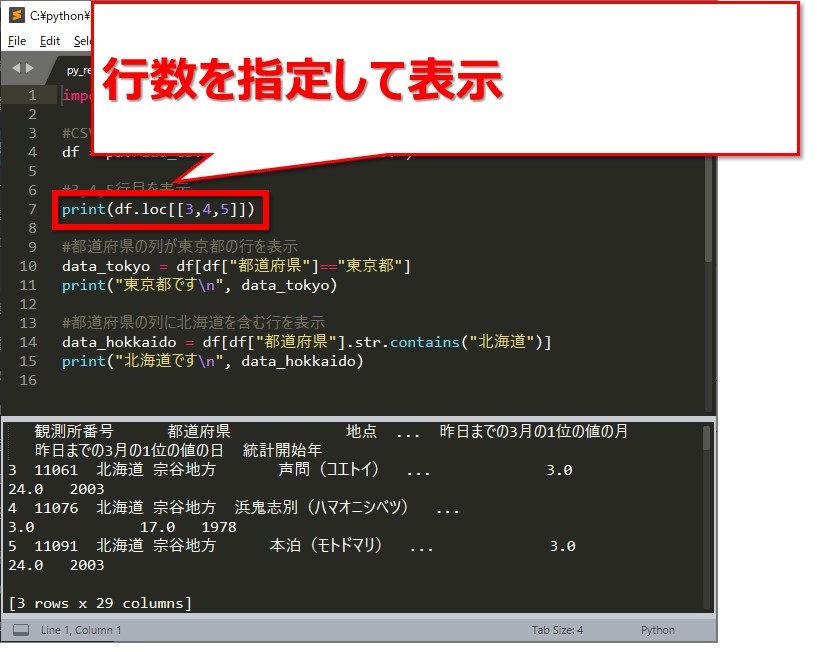
print(df.loc[[3,4,5]])
df.locのところで、dfの3,4,5行目を指定しています。
実行したところ、3行分表示されました。
条件に一致する行を指定する
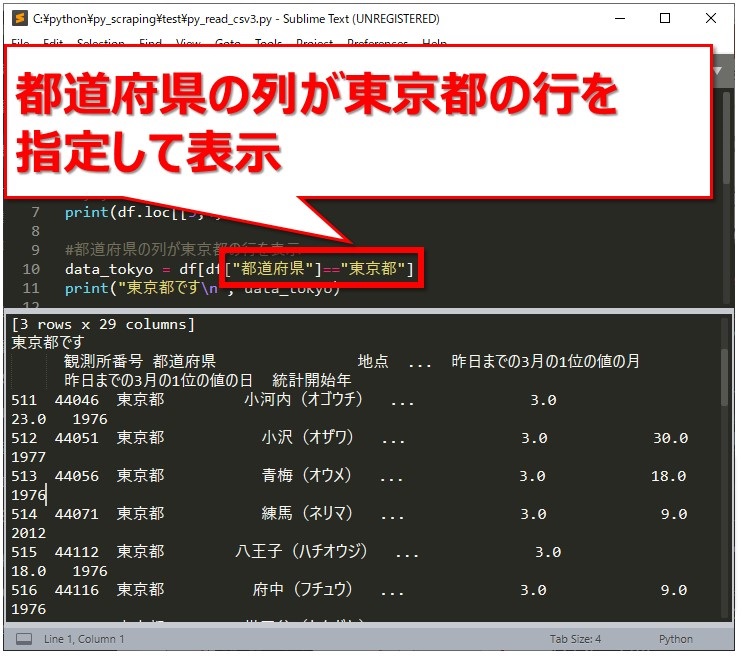
次は、都道府県の列が”東京都”と一致する行のみを指定します。
data_tokyo = df[df["都道府県"]=="東京都"]
dfの都道府県が東京都の行だけ、いったんdata_tokyoに格納しました。
print("東京都です\n", data_tokyo)
いったんデータフレームdata_tokyoに格納したデータを、ここで表示しています。
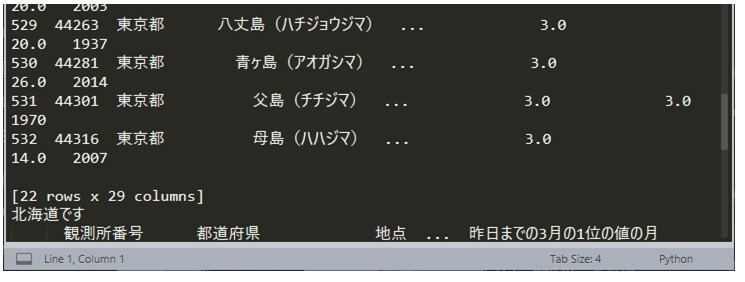
実行したところ、東京都の行が表示されました。
文字列を含む行を指定する
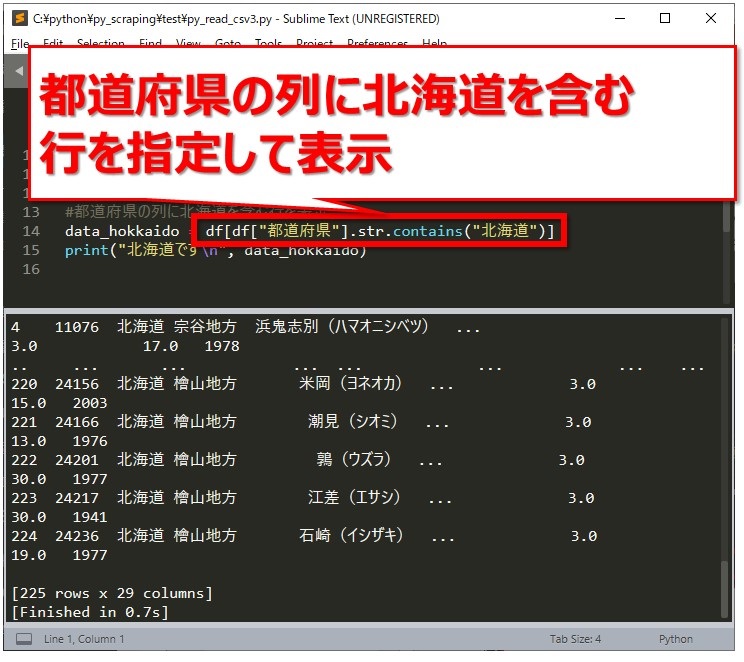
次はあいまい検索です。[br num=”1″]都道府県の列に北海道が含まれる行を表示させていきます。
「都道府県」という項目なのに、北海道 ○○地方という表現なんですよね。
data_hokkaido = df[df["都道府県"]=="北海道"]
と書いても、悲しいことに0件です。
北海道を含むなら、containsを使って次のように書きます。
data_hokkaido = df[df["都道府県"].str.contains("北海道")]
さっそく実行し、北海道 宗谷地方、北海道 檜山地方などが表示されました。
インターネット上のCSVファイルを読み込む
最後に、URLを指定して直接読み込んでいきます。
まず、ソースコードはこちら。[br num=”1″]のちほど解説しますね
import pandas as pd #CSVファイル読み込み URL = "http://www.data.jma.go.jp/obd/stats/data/mdrr/pre_rct/alltable/pre1h00_rct.csv" df = pd.read_csv(URL,encoding="SHIFT-JIS") #都道府県、地点、今日の最大値(mm)を表示 print(df[["都道府県","地点","今日の最大値(mm)"]])
実行したところ、CSVのデータが表示されました。[br num=”1″]画像内のコメント(3,4,5行目を表示)はミスです。

定数として使う想定なので、「URL」は大文字で書いています。
URL = "http://www.data.jma.go.jp/obd/stats/data/mdrr/pre_rct/alltable/pre1h00_rct.csv"
read_csvで、CSVファイルが置いてあるところを指定します。[br num=”1″]今回はURLのところですね。[br num=”1″]2つ目の引数で、文字コードのSHIFT-JISを指定します。
df = pd.read_csv(URL,encoding="SHIFT-JIS")
printで表示するところで、行ではなく、今回は列を指定しています。
print(df[["都道府県","地点","今日の最大値(mm)"]])
これで行も列も指定して表示できるようになりました。
まとめ:read_csvで読み込み、文字コードに気を付ける
外部ライブラリのpandasを使ってCSVファイルを読み込みました。
read_csvで、ローカルやインターネット上のCSVファイルを指定します。[br num=”1″]文字コードによってはエラーになります。[br num=”1″]指定方法など、参考にしてみてくださいね。


コメント Comments
コメント一覧
コメントはありません。
トラックバックURL
https://pro-blo.com/python/scraping/read-csv-with-pandas/trackback/