
CSVの入出力なら、Pandasが便利です。[br num=”1″]表データを扱うライブラリです。
もしも、まだインストールしていないという方でしたら、こちらの記事でインストール手順を参考にしてみてください。
CSV出力時は、次のようにto_csv関数を使います。
データフレーム.to_csv(ファイル名, encoding = 文字エンコーディング, index = False, header = False)
ヘッダーやインデックスを付ける場合、付けない場合、読み込んだCSVを出力する場合について、簡単なソースコードで紹介します。
ヘッダーやインデックスのオプションを指定せず出力した場合
to_csv関数のオプション(header, index)を付けない場合、ヘッダーやインデックスなしで出力されます。
次のソースコードでは、10行3列分の配列をデータフレームに格納して、dataフォルダのexport_data_list.csvファイルに出力しています。
import pandas as pd
#配列を定義
data_list = []
#配列の最後尾に足していく、10行分
for i in range(10):
data_list.append(["data_A"+str(i),"data_B"+str(i),"data_C"+str(i)])
#Pandasで、配列をDataFrameに格納
df = pd.DataFrame(data_list)
#CSVに出力
df.to_csv("data/export_data_list.csv")
出力されたCSVファイルを開いてみると、ヘッダーとインデックスが付いていることが分かります。
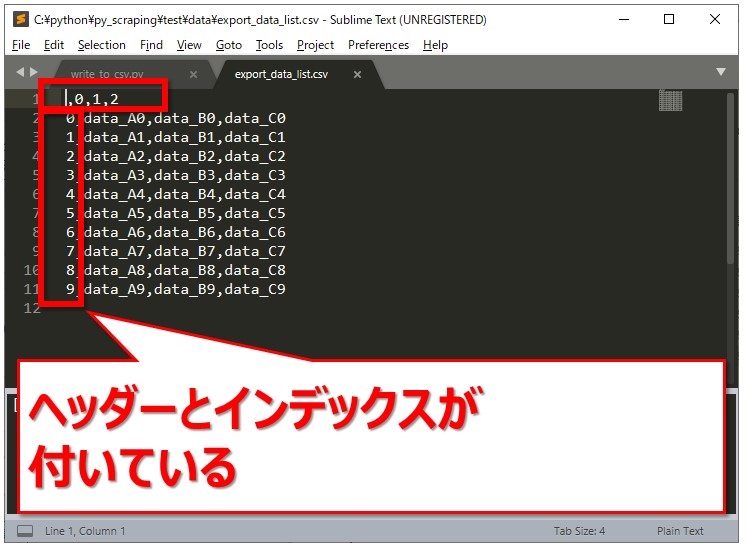
インデックスを付けない場合
インデックスを表示しない場合のオプションは、[br num=”1″]index = False です。
import pandas as pd
#配列を定義
data_list = []
#配列の最後尾に足していく、10行分
for i in range(10):
data_list.append(["data_A"+str(i),"data_B"+str(i),"data_C"+str(i)])
#Pandasで、配列をDataFrameに格納
df = pd.DataFrame(data_list)
#CSVに出力
df.to_csv("data/export_data_list.csv", index = False)
Falseの「F」は大文字ですので、小文字にしないよう注意してください。
保存されたCSVファイルを開いたところ、インデックスは消えてくれました。[br num=”1″]ヘッダーは相変わらず付いています。
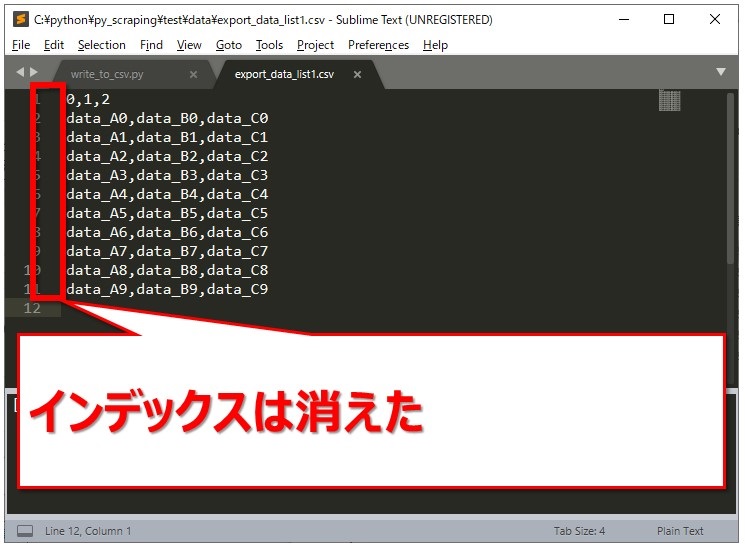
ヘッダーを付けない場合
インデックスを表示しない場合のオプションは、[br num=”1″]header = False です。
インデックスとヘッダーどちらも表示しないよう指定します。
import pandas as pd
#配列を定義
data_list = []
#配列の最後尾に足していく、10行分
for i in range(10):
data_list.append(["data_A"+str(i),"data_B"+str(i),"data_C"+str(i)])
#Pandasで、配列をDataFrameに格納
df = pd.DataFrame(data_list)
#CSVに出力
df.to_csv("data/export_data_list2.csv", index = False, header = False)
インデックスの場合と同様に、Falseの「F」は大文字ですので、小文字にしないよう注意してください。
出力されたCSVファイルを開き、ヘッダーもインデックスも付いていないことを確認できました。
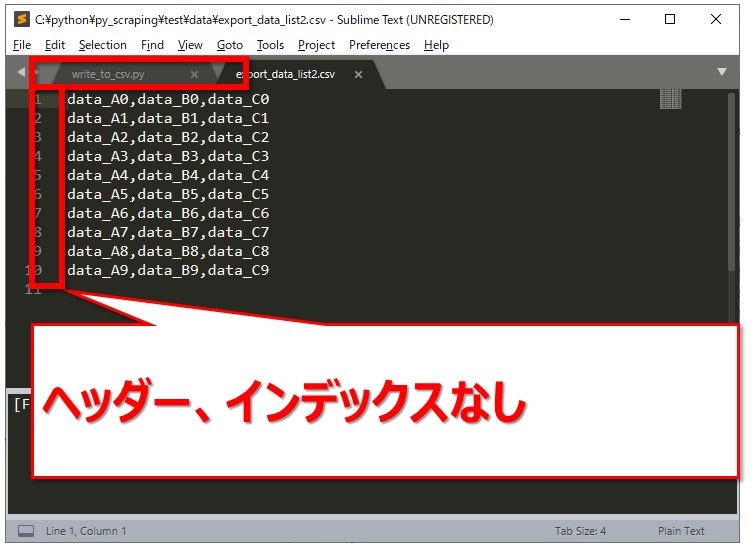
読み込んだCSVファイルを出力するときの、ヘッダーとインデックス
配列に値を格納してCSV出力した例では、ヘッダーは「,1,2,3」と付いていました。[br num=”1″]日本語などで既にヘッダーとして文字列が記載されているCSVファイルを読み込んでから、出力する場合はどうでしょうか。
CSVファイルの読み込みについては、こちらの記事で書いています。
そのまま出力
気象庁のオープンデータを使って紹介します。
出典:気象庁|「最新の気象データ」CSVダウンロード データ部掲載内容(1、3、6、12、24、48、72時間降水量)
最新のCSVファイル
データ量が多くて見づらくなるので、東京都の行、一部の列を抜き出しました。[br num=”1″]まずはオプション無しでCSV出力です。
import pandas as pd
#CSVファイル読み込み
URL = "http://www.data.jma.go.jp/obd/stats/data/mdrr/pre_rct/alltable/pre72h00_rct.csv"
df = pd.read_csv(URL,encoding="SHIFT-JIS")
df_tokyo = df[df["都道府県"] == "東京都"]
df_tokyo = df_tokyo[["都道府県","地点","現在時刻(日)","現在時刻(時)","今日の最大値(mm)"]]
#CSVに出力
df_tokyo.to_csv("data/export_data_list_web.csv")
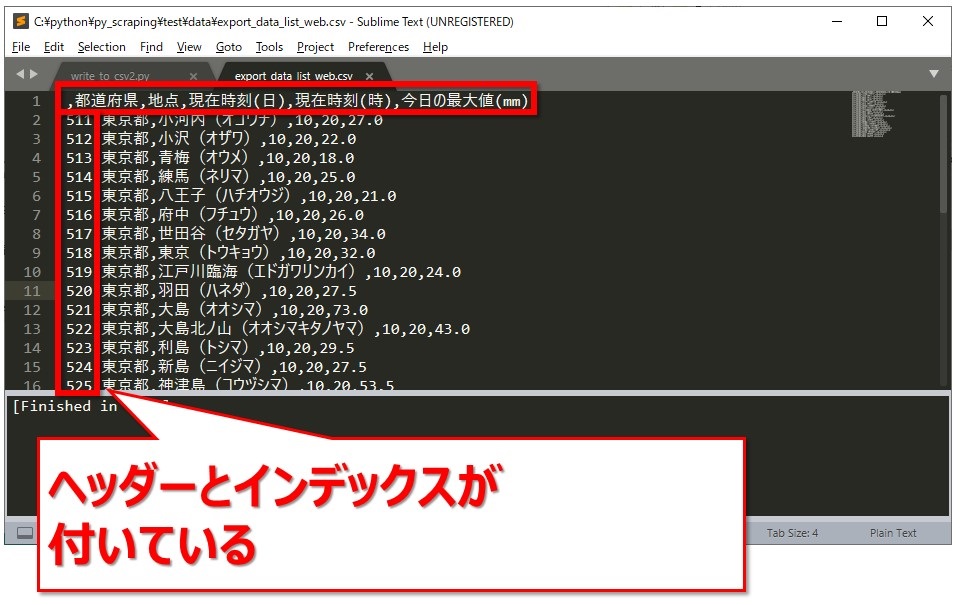
保存されたCSVファイルを確認したところ、ヘッダーもインデックスも付いていました。[br num=”1″]もともと北海道から順にデータが並んでいるCSVファイルだったので、東京都の行のインデックスは途中の511から始まっています。[br num=”1″]ヘッダーは「,1,2,3・・・」のような番号ではなく、読み込んだCSVファイル内のヘッダー名となりました。
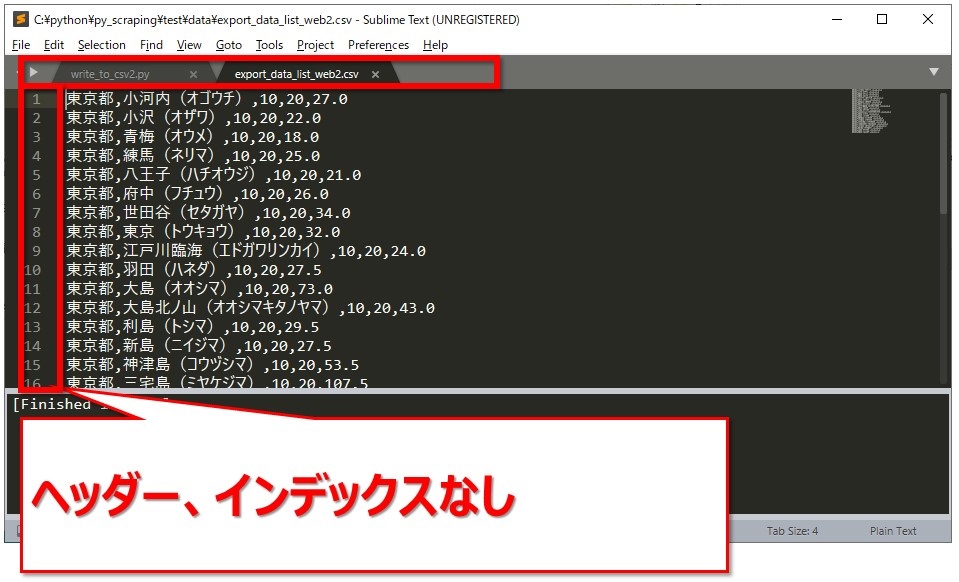
ヘッダー、インデックス無しで出力
こんどはヘッダーもインデックスもつけずに出力します。
オプションは、index = Falseと header = False。[br num=”1″]Falseの「F」だけ大文字になっている点に注意してくださいね。
import pandas as pd
#CSVファイル読み込み
URL = "http://www.data.jma.go.jp/obd/stats/data/mdrr/pre_rct/alltable/pre72h00_rct.csv"
df = pd.read_csv(URL,encoding="SHIFT-JIS")
df_tokyo = df[df["都道府県"] == "東京都"]
df_tokyo = df_tokyo[["都道府県","地点","現在時刻(日)","現在時刻(時)","今日の最大値(mm)"]]
#CSVに出力
df_tokyo.to_csv("data/export_data_list_web2.csv", index = False, header = False)
保存されたCSVファイルを開いたところ、ヘッダーもインデックスも付いていないことを確認できました。
まとめ:Pandasのto_csvを使うときの、ヘッダーとインデックス
CSVファイルにヘッダーやインデックスを出力しないとき、付けるオプションはこれです。[br num=”1″]index = Falseと header = False。
順番はどちらが先でも出力できました。[br num=”1″]注意点なども書いていますので、参考にしてみてくださいね。


コメント Comments
コメント一覧
コメントはありません。
トラックバックURL
https://pro-blo.com/python/scraping/pandas-to-csv-remove-header/trackback/